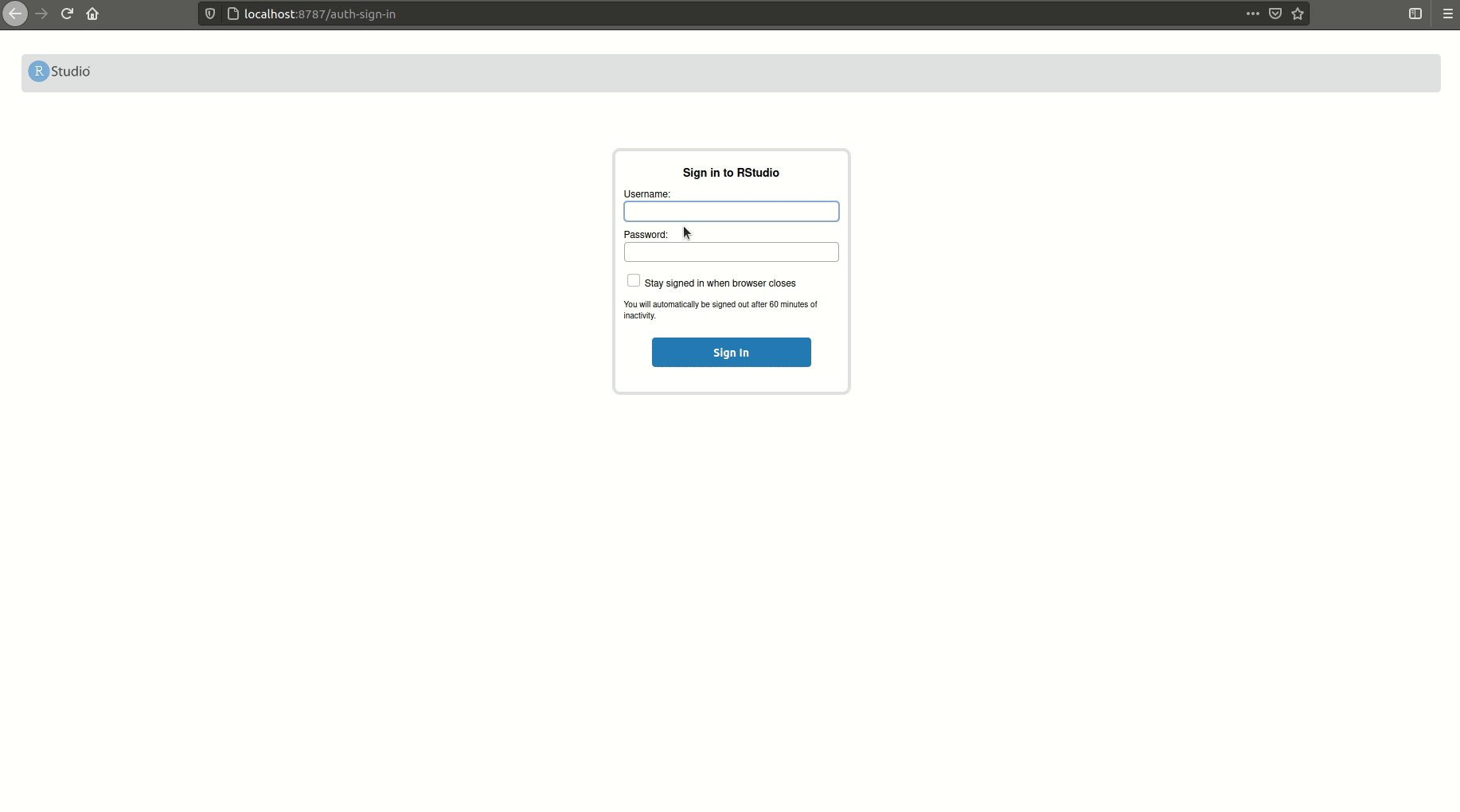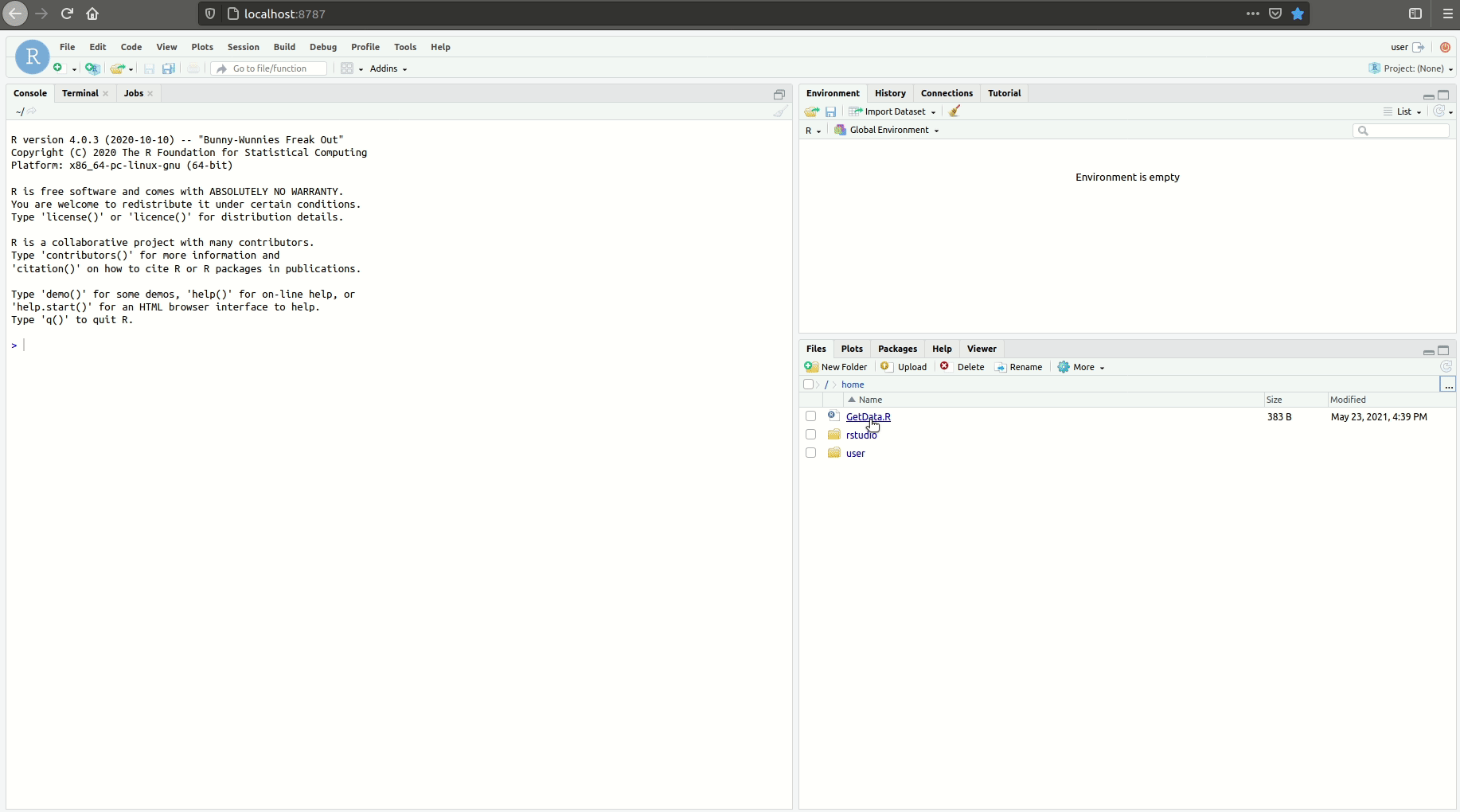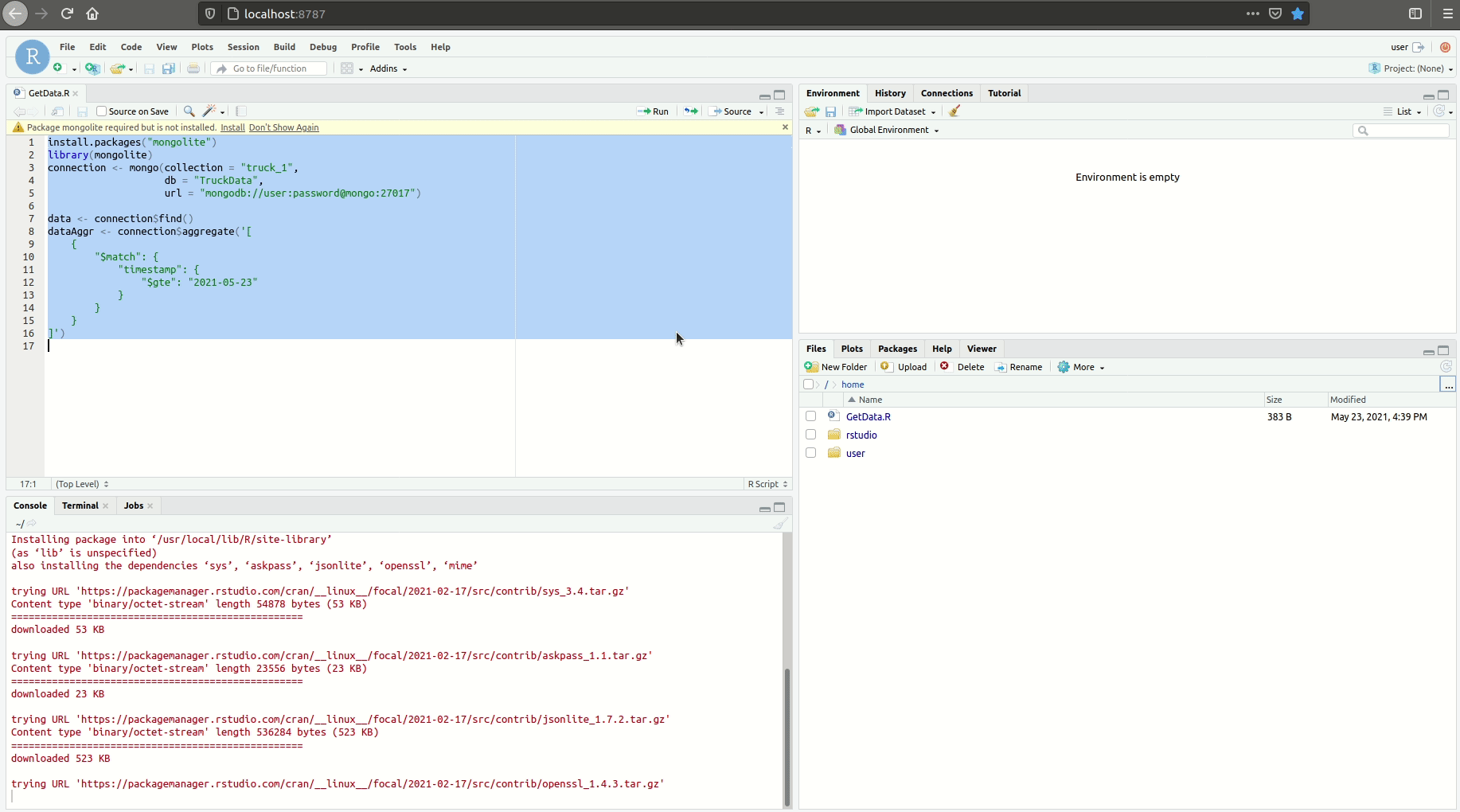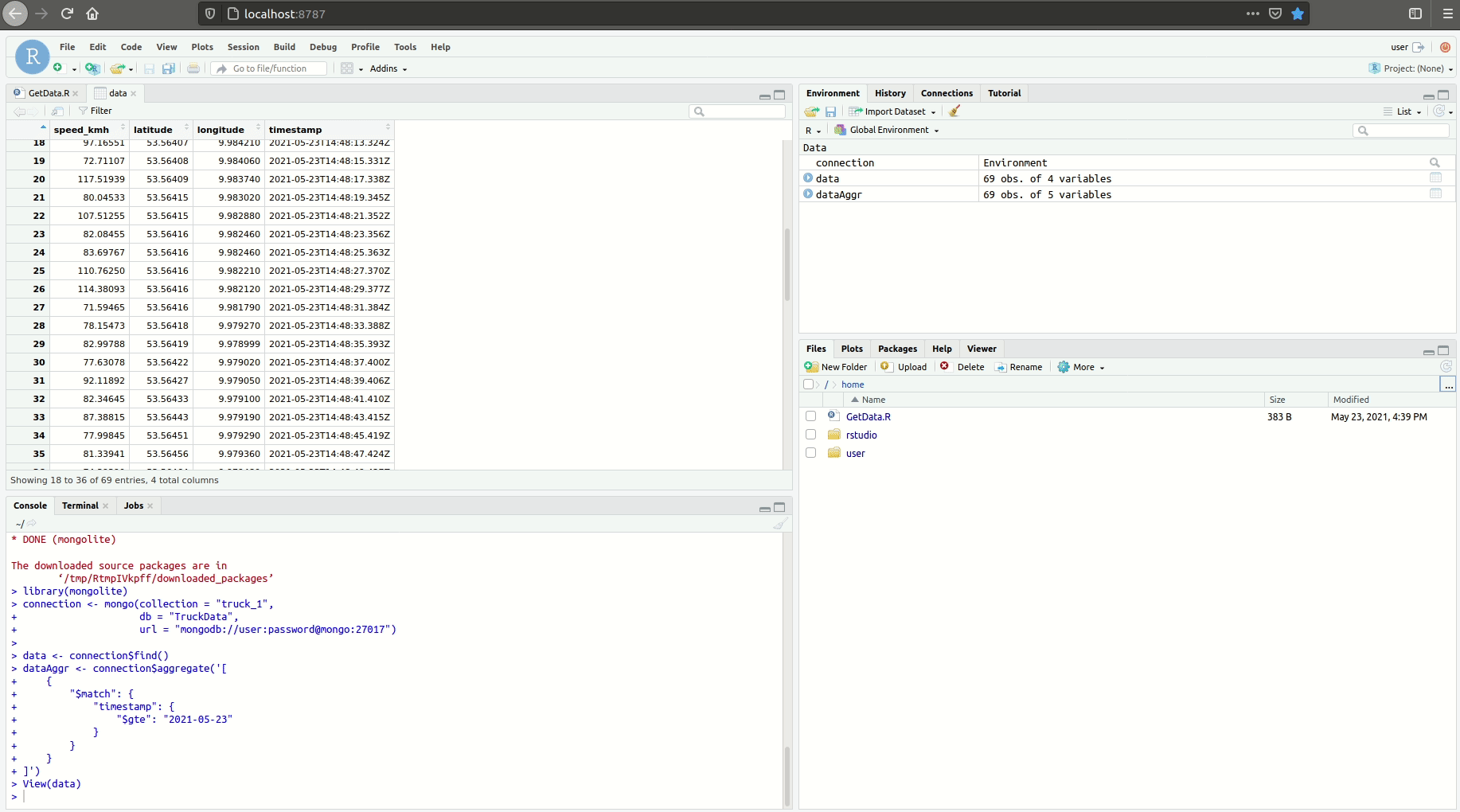
Before using the tool you must set your api key in one of this file or you can start without creating it and you will be prompted to provide the data:
These can be installed via PIP or a package manager.
Example of installing all dependencies using pip:
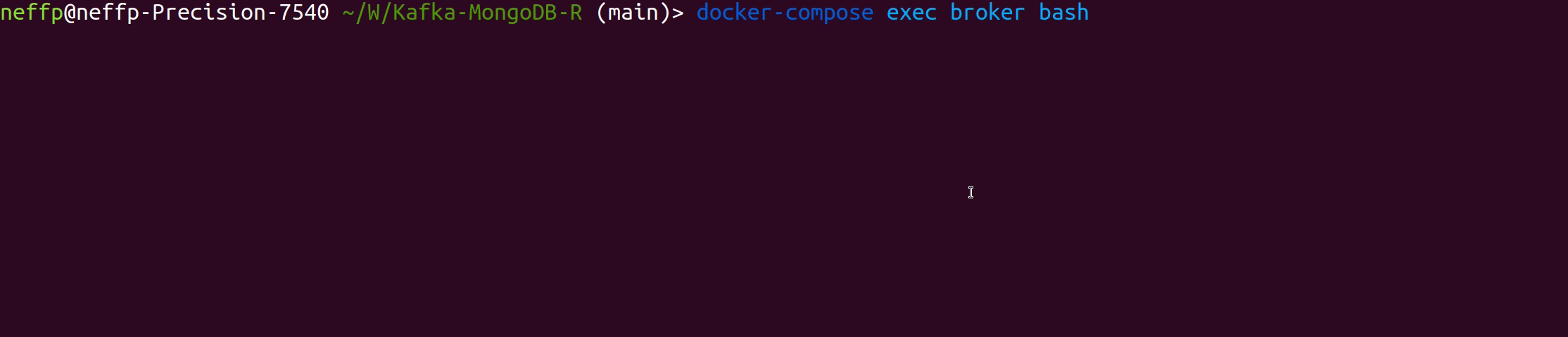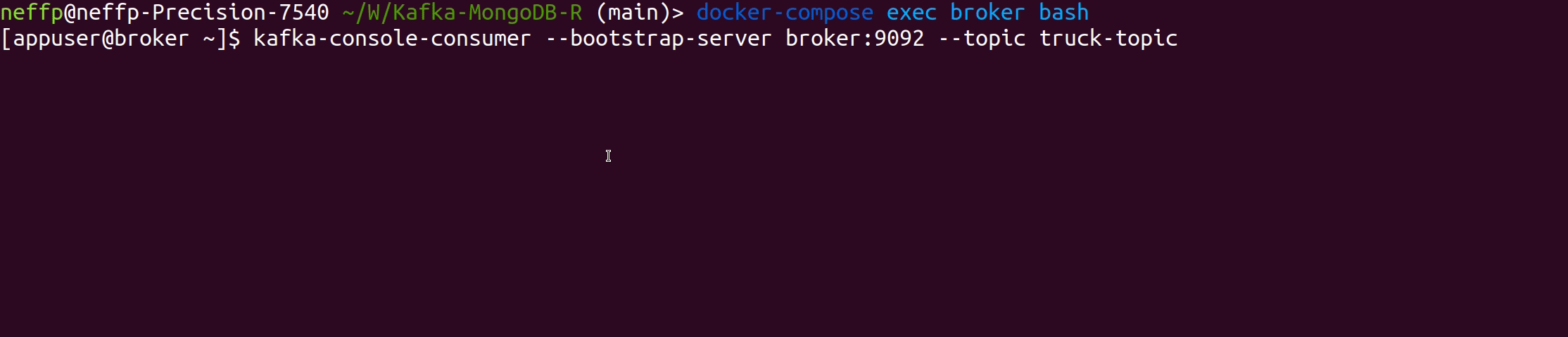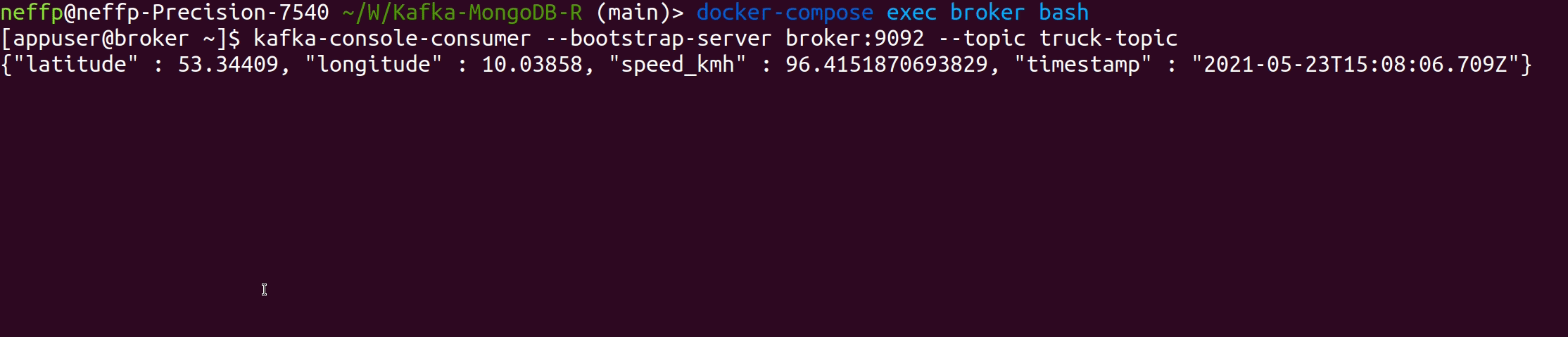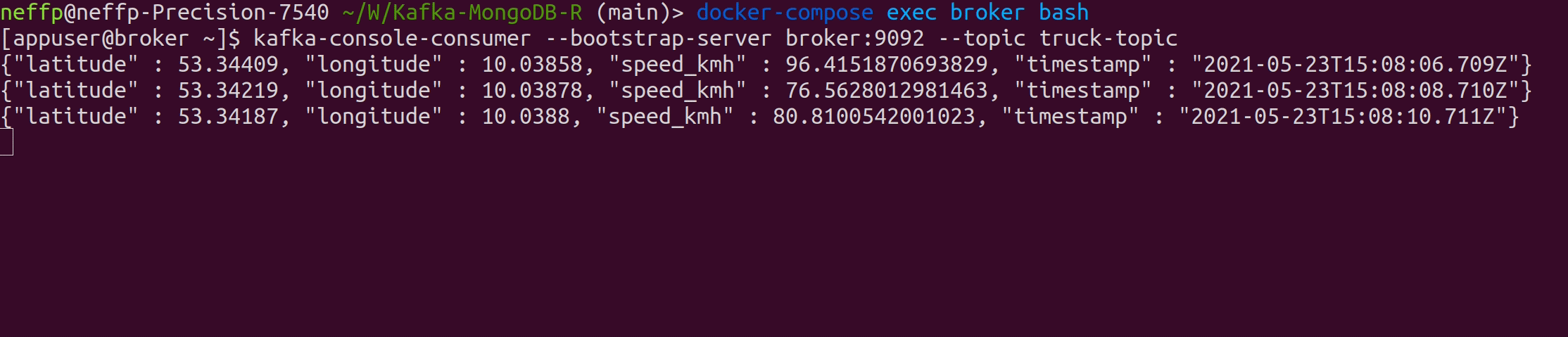
vt -h
usage: value [-h] [-fi] [-udb USERDB] [-fs] [-f] [-fr] [-u] [-ur] [-d] [-i]
[-w] [-s] [-si] [-et] [-rai] [-itu] [-cw] [-dep] [-eo] [-snr]
[-srct] [-tir] [-wir] [-rbgi] [-rbi] [-agi] [-dbc] [-ac] [-gc]
[--get-comments-before DATE] [-v] [-j] [--csv] [-rr] [-rj] [-V]
[-r] [--delete] [--date DATE] [--period PERIOD] [--repeat REPEAT]
[--notify-url NOTIFY_URL] [--notify-changes-only] [-wh] [-wht]
[-pdns] [--asn] [-aso] [--country] [--subdomains]
[--domain-siblings] [-cat] [-alc] [-alk] [-opi] [--drweb-cat]
[-adi] [-wdi] [-tm] [-wt] [-bd] [-wd] [-du] [--pcaps] [--samples]
[-dds] [-uds] [-dc] [-uc] [-drs] [-urs] [-pe]
[-esa SAVE_ATTACHMENT] [-peo] [-bh] [-bn] [-bp] [-bs] [-dl]
[-nm NAME] [-dt DOWNLOAD_THREADS] [--pcap] [--clusters]
[--distribution-files] [--distribution-urls] [--before BEFORE]
[--after AFTER] [--reports] [--limit LIMIT] [--allinfo] [--rules]
[--list] [--create FILE] [--update FILE] [--retro FILE]
[--delete_rule DELETE_RULE] [--share]
[--update_ruleset UPDATE_RULESET] [--disable DISABLE]
[--enable ENABLE]
[value [value ...]]
Scan/Search/ReScan/JSON parse
positional arguments:
value Enter the Hash, Path to File(s) or Url(s)
optional arguments:
-h, --help show this help message and exit
-fi, --file-info Get PE file info, all data extracted offline, for work
you need have installed PEUTILS library
-udb USERDB, --userdb USERDB
Path to your userdb file, works with --file-info
option only
-fs, --file-search File(s) search, this option, don't upload file to
VirusTotal, just search by hash, support linux name
wildcard, example: /home/user/*malware*, if file was
scanned, you will see scan info, for full scan report
use verbose mode, and dump if you want save already
scanned samples
-f, --file-scan File(s) scan, support linux name wildcard, example:
/home/user/*malware*, if file was scanned, you will
see scan info, for full scan report use verbose mode,
and dump if you want save already scanned samples
-fr, --file-scan-recursive
Recursive dir walk, use this instead of --file-scan if
you want recursive
-u, --url-scan Url scan, support space separated list, Max 4 urls (or
25 if you have private api), but you can provide more
urls, for example with public api, 5 url - this will
do 2 requests first with 4 url and other one with only
1, or you can specify file filename with one url per
line
-ur, --url-report Url(s) report, support space separated list, Max 4 (or
25 if you have private api) urls, you can use --url-
report --url-scan options for analyzing url(s) if they
are not in VT data base, read preview description
about more then max limits or file with urls
-d, --domain-info Retrieves a report on a given domain (PRIVATE API
ONLY! including the information recorded by
VirusTotal's Passive DNS infrastructure)
-i, --ip-info A valid IPv4 address in dotted quad notation, for the
time being only IPv4 addresses are supported.
-w, --walk Work with domain-info, will walk through all detected
ips and get information, can be provided ip parameters
to get only specific information
-s, --search A md5/sha1/sha256 hash for which you want to retrieve
the most recent report. You may also specify a scan_id
(sha256-timestamp as returned by the scan API) to
access a specific report. You can also specify a space
separated list made up of a combination of hashes and
scan_ids Public API up to 4 items/Private API up to 25
items, this allows you to perform a batch request with
one single call.
-si, --search-intelligence
Search query, help can be found here -
https://www.virustotal.com/intelligence/help/
-et, --email-template
Table format template for email
-ac, --add-comment The actual review, you can tag it using the "#"
twitter-like syntax (e.g. #disinfection #zbot) and
reference users using the "@" syntax (e.g.
@VirusTotalTeam). supported hashes MD5/SHA1/SHA256
-gc, --get-comments Either a md5/sha1/sha256 hash of the file or the URL
itself you want to retrieve
--get-comments-before DATE
A datetime token that allows you to iterate over all
comments on a specific item whenever it has been
commented on more than 25 times. Token format
20120725170000 or 2012-07-25 17 00 00 or 2012-07-25
17:00:00
-v, --verbose Turn on verbosity of VT reports
-j, --dump Dumps the full VT report to file (VTDL{md5}.json), if
you (re)scan many files/urls, their json data will be
dumped to separated files
--csv Dumps the AV's detections to file (VTDL{scan_id}.csv)
-rr, --return-raw Return raw json, in case if used as library and want
parse in other way
-rj, --return-json Return json with parts activated, for example -p for
passive dns, etc
-V, --version Show version and exit
All information related:
-rai, --report-all-info
If specified and set to one, the call will return
additional info, other than the antivirus results, on
the file being queried. This additional info includes
the output of several tools acting on the file (PDFiD,
ExifTool, sigcheck, TrID, etc.), metadata regarding
VirusTotal submissions (number of unique sources that
have sent the file in the past, first seen date, last
seen date, etc.), and the output of in-house
technologies such as a behavioural sandbox.
-itu, --ITW-urls In the wild urls
-cw, --compressedview
Contains information about extensions, file_types,
tags, lowest and highest datetime, num children
detected, type, uncompressed_size, vhash, children
-dep, --detailed-email-parents
Contains information about emails, as Subject, sender,
receiver(s), full email, and email hash to download it
-eo, --email-original
Will retrieve original email and process it
-snr, --snort Get Snort results
-srct, --suricata Get Suricata results
-tir, --traffic-inspection
Get Traffic inspection info
-wir, --wireshark-info
Get Wireshark info
-rbgi, --rombios-generator-info
Get RomBios generator info
-rbi, --rombioscheck-info
Get RomBiosCheck info
-agi, --androidguard-info
Get AndroidGuard info
-dbc, --debcheck-info
Get DebCheck info, also include ios IPA
Rescan options:
-r, --rescan Allows you to rescan files in VirusTotal's file store
without having to resubmit them, thus saving
bandwidth, support space separated list, MAX 25
hashes, can be local files, hashes will be generated
on the fly, support linux wildmask
--delete A md5/sha1/sha256 hash for which you want to delete
the scheduled scan
--date DATE A Date in one of this formats (example: 20120725170000
or 2012-07-25 17 00 00 or 2012-07-25 17:00:00) in
which the rescan should be performed. If not specified
the rescan will be performed immediately.
--period PERIOD Period in days in which the file should be rescanned.
If this argument is provided the file will be
rescanned periodically every period days, if not, the
rescan is performed once and not repeated again.
--repeat REPEAT Used in conjunction with period to specify the number
of times the file should be rescanned. If this
argument is provided the file will be rescanned the
given amount of times, if not, the file will be
rescanned indefinitely.
File scan/Rescan shared options:
--notify-url NOTIFY_URL
An URL where a POST notification should be sent when
the scan finishes.
--notify-changes-only
Used in conjunction with --notify-url. Indicates if
POST notifications should be sent only if the scan
results differ from the previous one.
Domain/IP shared verbose mode options, by default just show resolved IPs/Passive DNS:
-wh, --whois Whois data
-wht, --whois-timestamp
Whois timestamp
-pdns, --resolutions Passive DNS resolves
--asn ASN number
-aso, --as-owner AS details
--country Country
--subdomains Subdomains
--domain-siblings Domain siblings
-cat, --categories Categories
-alc, --alexa-cat Alexa category
-alk, --alexa-rank Alexa rank
-opi, --opera-info Opera info
--drweb-cat Dr.Web Category
-adi, --alexa-domain-info
Just Domain option: Show Alexa domain info
-wdi, --wot-domain-info
Just Domain option: Show WOT domain info
-tm, --trendmicro Just Domain option: Show TrendMicro category info
-wt, --websense-threatseeker
Just Domain option: Show Websense ThreatSeeker
category
-bd, --bitdefender Just Domain option: Show BitDefender category
-wd, --webutation-domain
Just Domain option: Show Webutation domain info
-du, --detected-urls Just Domain option: Show latest detected URLs
--pcaps Just Domain option: Show all pcaps hashes
--samples Will activate -dds -uds -dc -uc -drs -urs
-dds, --detected-downloaded-samples
Domain/Ip options: Show latest detected files that
were downloaded from this ip
-uds, --undetected-downloaded-samples
Domain/Ip options: Show latest undetected files that
were downloaded from this domain/ip
-dc, --detected-communicated
Domain/Ip Show latest detected files that communicate
with this domain/ip
-uc, --undetected-communicated
Domain/Ip Show latest undetected files that
communicate with this domain/ip
-drs, --detected-referrer-samples
Undetected referrer samples
-urs, --undetected-referrer-samples
Undetected referrer samples
Process emails:
-pe, --parse-email Parse email, can be string or file
-esa SAVE_ATTACHMENT, --save-attachment SAVE_ATTACHMENT
Save email attachment, path where to store
-peo, --parse-email-outlook
Parse outlook .msg, can be string or file
Behaviour options:
-bh, --behaviour The md5/sha1/sha256 hash of the file whose dynamic
behavioural report you want to retrieve. VirusTotal
runs a distributed setup of Cuckoo sandbox machines
that execute the files we receive. Execution is
attempted only once, upon first submission to
VirusTotal, and only Portable Executables under 10MB
in size are ran. The execution of files is a best
effort process, hence, there are no guarantees about a
report being generated for a given file in our
dataset. a file did indeed produce a behavioural
report, a summary of it can be obtained by using the
file scan lookup call providing the additional HTTP
POST parameter allinfo=1. The summary will appear
under the behaviour-v1 property of the additional_info
field in the JSON report.This API allows you to
retrieve the full JSON report of the files execution
as outputted by the Cuckoo JSON report encoder.
-bn, --behavior-network
Show network activity
-bp, --behavior-process
Show processes
-bs, --behavior-summary
Show summary
Download options:
-dl, --download The md5/sha1/sha256 hash of the file you want to
download or txt file with .txt extension, with hashes,
or hash and type, one by line, for example: hash,pcap
or only hash. Will save with hash as name, can be
space separated list of hashes to download
-nm NAME, --name NAME
Name with which file will saved when download it
-dt DOWNLOAD_THREADS, --download-threads DOWNLOAD_THREADS
Number of simultaneous downloaders
Additional options:
--pcap The md5/sha1/sha256 hash of the file whose network
traffic dump you want to retrieve. Will save as
hash.pcap
--clusters A specific day for which we want to access the
clustering details, example: 2013-09-10
--distribution-files Timestamps are just integer numbers where higher
values mean more recent files. Both before and after
parameters are optional, if they are not provided the
oldest files in the queue are returned in timestamp
ascending order.
--distribution-urls Timestamps are just integer numbers where higher
values mean more recent urls. Both before and after
parameters are optional, if they are not provided the
oldest urls in the queue are returned in timestamp
ascending order.
Distribution options:
--before BEFORE File/Url option. Retrieve files/urls received before
the given timestamp, in timestamp descending order.
--after AFTER File/Url option. Retrieve files/urls received after
the given timestamp, in timestamp ascending order.
--reports Include the files' antivirus results in the response.
Possible values are 'true' or 'false' (default value
is 'false').
--limit LIMIT File/Url option. Retrieve limit file items at most
(default: 1000).
--allinfo will include the results for each particular URL scan
(in exactly the same format as the URL scan retrieving
API). If the parameter is not specified, each item
returned will only contain the scanned URL and its
detection ratio.
Rules management options:
--rules Manage VTI hunting rules, REQUIRED for rules management
--list List names/ids of Yara rules stored on VT
--create FILE Add a Yara rule to VT (File Name used as RuleName
--update FILE Update a Yara rule on VT (File Name used as RuleName
and must include RuleName
--retro FILE Submit Yara rule to VT RetroHunt (File Name used as
RuleName and must include RuleName
--delete_rule DELETE_RULE
Delete a Yara rule from VT (By Name)
--share Shares rule with user
--update_ruleset UPDATE_RULESET
Ruleset name to update
--disable DISABLE Disable a Yara rule from VT (By Name)
--enable ENABLE Enable a Yara rule from VT (By Name)